
Improving FreeImage.Standard performance with Span<T>
There have been a lot of really impressive performance improvements in .NET over the past couple of years:
- Span<T> - represents an area of contiguous memory (managed or unmanaged)
- ArrayPool<T> - provides a pool of reusable array objects
- stackallocate - allocate a block of memory on the stack
These types do have introduce some additional complexity, for example:
- Accessing the rented buffer after returning it to the ArrayPool will result in undefined behaviour
- Span
can only be allocated on the stack, so you can't store a reference to it (e.g. in a property)
I've followed these developments with some interest - it's been great to see Microsoft thoroughly disproving the people who claim that C# / .NET (and managed runtimes in general) are slow by building the third-fastest web server in the world on .NET Core.
I forked FreeImage-dotnet-core a few months ago, creating FreeImage.Standard. I have various personal and work projects that use FreeImage and I wanted to tackle some of the interop frustrations that I'd run into using other people's wrappers.
I've spent a few hours this weekend improving the performance of the FreeImage.Standard stream IO functions. This was very much a first pass and the goal was to see what was possible without disturbing too much of the code.
Tools
The first step in improving performance of any code is to measure the performance.
It's not good enough to say that the code was "slow" and now it is "fast". We need to know how slow and how fast in order to quantify what improvement has been made.
BenchmarkDotNet is a fantastic tool designed to make it easy for you to measure performance without making common mistakes that could affect your results. It also allows direct comparison between the same code running under .NET Framework and .NET Core.
Visual Studio has a built-in memory allocation profiler which allows you to dig into your application's memory allocations in much more detail - including allocation counts by object type, call stacks and hot path analysis, etc.
Initial Performance
I had been benchmarking a workflow in a production application and noticed that it allocated a lot of memory per operation (3.95 GB). This wasn't totally unexpected given that it is processing large images, but it did feel like the number was on the high side. The benchmark also showed high garbage collection counts.

Basic Improvements
Digging in with the Visual Studio profiler showed that the hot path ended up in the streamWrite() method in the FreeImage wrapper.
I decided to update streamWrite() in FreeImage.Standard to use the new Span<T> and ArrayPool<T> APIs. This turned out to only require fairly minor tweaks to the existing code - most of my time was spent writing unit tests (to prove my changes were correct) and benchmarks (to measure the difference in performance).
The original code looks like this:
static unsafe uint streamWrite(IntPtr buffer, uint size, uint count, fi_handle handle) { Stream stream = handle.GetObject() as Stream; uint writeCount = 0; // Allocate a new byte[] every time byte[] bufferTemp = new byte[size]; byte* ptr = (byte*)buffer; while (writeCount < count) { // Copy the unamanaged buffer into the new array, one byte at a time for (int i = 0; i < size; i++, ptr++) { bufferTemp[i] = *ptr; } try { stream.Write(bufferTemp, 0, bufferTemp.Length); } catch { return writeCount; } writeCount++; } return writeCount; }
After my changes, it now looks like this:
static unsafe uint streamWrite(IntPtr buffer, uint size, uint count, fi_handle handle) { Stream stream = handle.GetObject() as Stream; int sizeInt = (int)size; var arrayPool = ArrayPool<byte>.Shared; // Use the shared ArrayPool for byte arrays byte* ptr = (byte*)buffer; uint writeCount = 0; byte[] managedBuffer = arrayPool.Rent(sizeInt); // Rent an existing buffer from the ArrayPool try { while (writeCount < count) { // Represent the source (unmanaged) buffer as a ReadOnlySpan<byte> var source = new ReadOnlySpan<byte>(ptr, sizeInt); ptr += sizeInt; // Copy from the source to the managed buffer - rather than doing this one byte at a time, just leave // the copy mechanism to the runtime (I am assuming it will do a block copy for performance) source.CopyTo(managedBuffer); stream.Write(managedBuffer, 0, sizeInt); writeCount++; } return writeCount; } finally { // Return the rented buffer back to the pool for reuse - do not access managedBuffer again! arrayPool.Return(managedBuffer); } }
Pretty similar, right?
This fairly small change resulted execution time improving almost 2.6x on .NET Framework and just over 3x on .NET Core!
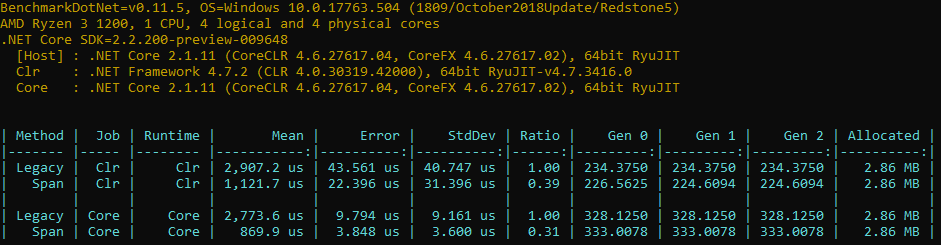
I proceeded to update the streamRead() method in the same vein:

Again, a small change to the code resulted in a 33% performance improvement on .NET Framework and 43% on .NET Core.
Real-World Impact
I updated the production code to use the updated FreeImage.Standard assemblies and re-ran the benchmarks.
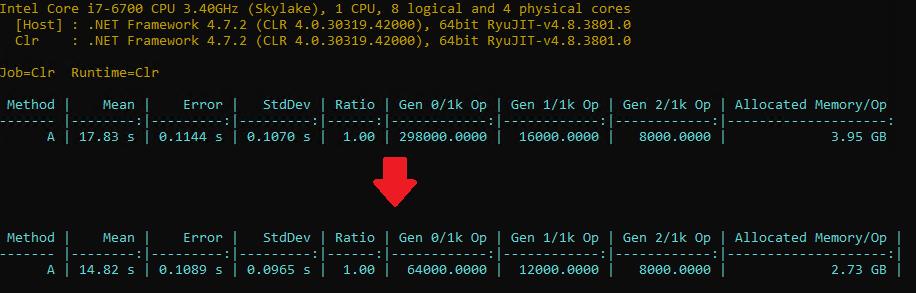
Straight away, we can see that the average time per operation has decreased by 3 seconds - doesn't sound like a great improvement, but it adds up:
- Throughput up by 984 ops/day (+20%)
- Reduced allocations by 3.2 TB/day (-16%)
- Reduced Gen0 collections 79%
- Reduced Gen1 collections 25%
- Reduced number of allocations by 74%
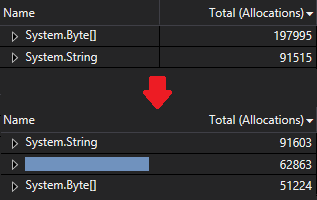
System.Byte[]has gone from (by far) the highest source of allocations to the third highest
Conclusion
The new Span